
Nowadays, Docker is everywhere: from your local dev environment to your production Kubernetes cluster. Let’s say you just built a Docker image for your latest application, and you run it locally to test it out. It runs perfectly, but when you try to stop it, it takes 10 seconds to do so. However, when you just run the application outside of docker, it stops quite quickly. What is happening here? Is Docker just slow? Why does my container take so long to stop? Chances are, your Docker container is not configured properly. More precisely, your application never receives the signal that tells it to shut down, and is improperly stopped. This can have an unexpectedly huge impact on a production environment. We’ll explain exactly why here.
Context: The process tree and signal management
Unix process trees
Whenever a command is issued in a Unix environment, whether in the foreground like when you run ls in your terminal, or in the background, a process handles that command. Those processes run the program, but also hold a lot of metadata for the system to manage.
For example, each process has a PID, a number that is its unique identifier. A process also has a PPID, which is the ID of its parent process.
Unix processes are ordered in a tree. Each process can have child processes, and all have a parent process. All except the very first process, the PID 1.
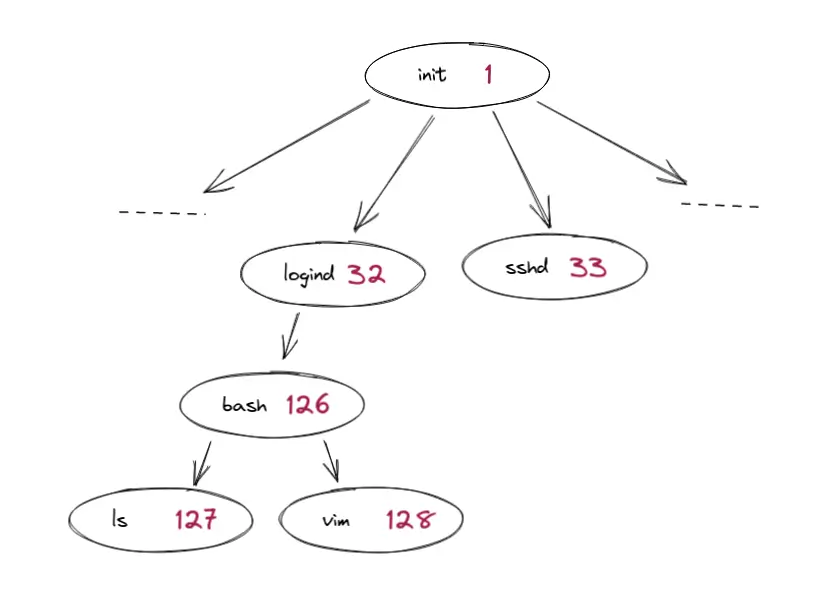
PID 1, also known as init, is the common ancestor of all processes and is the foundation on which all of them run. Thus, you can imagine its importance.
Processes’ lifecycle
The parent process has many responsibilities relating to the lifecycle. If a process terminates, some of its data is kept until the parent collects it. If the parent does not collect it, it becomes a zombie process. If the parent terminates, its child processes become orphaned and have to be adopted by another process: they are often adopted by init.
Parent processes also have a very important job: forwarding OS signals to children.
OS signals
OS signals are used to communicate information on things that are happening or have happened so that processes can react to them. For example, SIGINT is the signal that is sent when you press CTRL+C on a program. This causes the program to stop running.
The signals that interest us are SIGTERM and SIGKILL. SIGTERM indicates that someone terminated the process so it has to perform clean-up and stop; this is the signal that is sent to our container when we stop it. SIGKILL orders the process to terminate instantly, without performing any cleanup. As you can imagine, we want to avoid SIGKILLs as much as possible, as they are not a proper way to terminate a process.
Now that we know how process management works in a UNIX environment, how does this relate to our current problem?
End of the lifecycle for containers
How it should happen
Here’s what should happen if everything went correctly.
A Docker container named mycontainer is running. I want to stop it. I run docker stop mycontainer.
The PID 1 receives a SIGTERM signal. It forwards this signal to its children. All the children stop and send a SIGCHILD signal with their exit status (0 if everything went well) to the parent to indicate that they have been terminated. When PID 1 does not have any children anymore, it terminates with an exit status of 0.
What happens when not configured properly
If your container is not configured properly, multiple things can go wrong. In this article, I will focus on one problem: signal propagation, or the lack thereof.
In that case, the PID 1 receives the SIGTERM signal.
The PID 1 does not propagate the signal, because it does not know how to. For example, bash scripts do not naturally forward OS signals to child processes. However, the pid 1 still waits for its children to be terminated. They never do, as they do not know that they have to terminate.
After 10 seconds, docker sends a SIGKILL to the pid 1. It immediately terminates.
Alright, that clarifies the problem. However, it just adds ten seconds to my lifecycle, at a moment I don’t even need my container anymore, so why does this matter?
How a bad lifecycle impacts teams and users
For local development
First of all, 10 seconds is quite a long time. Imagine developers creating a docker-compose file for a webservice, using a container whose PID 1 does not propagate signals. They are debugging the connection between the webservice and its backend. Every time they want to re-create containers, the webservice will take 10 seconds to stop. That’s ten seconds of waiting, nothing else.
This is how I first identified the problem: I was building containers and getting tired of waiting for them to stop.
In production environments
However, this is more than fatigue. It can have a real impact on production environments.
In Kubernetes, instead of waiting 10 seconds to send a SIGKILL, the default behavior is to wait for 30 seconds.
Let’s say that you have a misconfigured app that would take 3 seconds to stop if everything went well. This means that everything that you do takes 10 times more time. You want to roll out the application, which has 10 pods running. You allow a maximum number of pods of 11, and a minimum of 10. Each pod has to stop one after the other. That’s at least 5 minutes of waiting, not counting how long it takes for a pod to start!
If the pod was configured correctly, it would take 30 seconds total. On huge infrastructures, this makes all the difference.
Gitlab wrote a great article on how this issue impacted them directly. When their application failed, the pod was taken off the service and took 30 seconds to be restarted. However, because of how tcp connections work in Go, even if the pod was not behind a service anymore, as long as it was running, it still received requests. Because the application failed, these requests ended up in 502 responses.
Their problem was solved when their application started receiving the SIGTERM correctly. When the app needed to stop, it did so instantly, which ended the TCP connections, instead of keeping them open for 30 seconds while waiting for a SIGKILL.
Many more problems can be imagined, like forcefully ending a process while it is writing to disk or writing in a locked file.
That looks quite bad, I would not want this to happen in my production environment. So how do I avoid this, and apply Docker good practices to have clean process management?
How to solve this problem efficiently
The first step is to make sure that no signal propagation is involved, by having your process as pid 1. The second is to make sure your process catches SIGTERMs properly.
One Docker container = one init process
To avoid having poor signal propagation handling, we can avoid needing this propagation entirely! To do this, the program that we run should be pid 1.
In a dockerfile, you can specify the command that runs in the container with ENTRYPOINT or CMD. CMD should be used when you want to define the command ran by the container, and make it easy to override it. ENTRYPOINT should be when you don’t want it to be overridden easily. You can combine the two if you want to pass a command to ****ENTRYPOINT and easily overridden parameters to CMD.
The way you write the command after ENTRYPOINT and CMD will completely change the way it is managed. There are two formats: shell and exec.
The following dockerfile uses shell format:
FROM python:latest
WORKDIR /app
COPY my_program.py
ENTRYPOINT python3 my_program.pyThe entrypoint will start a shell, which will run the program. This is equivalent to running sh -c python3 my_program.py. The shell is thus pid 1. This is not what we want: we want our python program to be pid 1.
This dockerfile uses exec format:
FROM python:latest
WORKDIR /app
COPY my_program.py
ENTRYPOINT ["python3", "my_program.py"]The entrypoint will run our program directly as pid 1. This is perfect for us! The program directly receives the SIGTERM, and finishes.
Thus, you should always use the exec format so as to not work through unneeded shells.
Replace a bash script process with exec
If using a bash script to run a few commands before the main one (migrations in a database, changing the /etc/hosts…), you can run the last command with exec. For example,
#!/bin/bash
./migrate_database_schema.sh
exec python3 my_program.pyThis executes the command by replacing the current process. The shell is destroyed, and if it was started in docker with the exec format and was pid 1, the python program becomes pid 1.
Configuring processes to trap SIGTERM signals
If you applied the exec form and your container still takes 10 seconds to stop, chances are, your program does not handle SIGTERM. For example, if your entrypoint is this bash executable:
#!/bin/bash
while true
do
echo "Hi, I'm bash !"
sleep 1
doneWhen you try to stop this greatly useful container, even if your main script is PID 1, it will take 10 seconds to stop. Why? Bash executables handle SIGTERMs, but in linux, PID 1 is unkillable by default. You have to be more explicit by setting handlers. This makes sense: you would not want to stop an init process by accident, as it has heavy consequences on the whole system.
You have to trap the TERM signal and tell it to exit the program when receiving the signal. Like so:
#!/bin/bash
trap "exit" TERM
while true
do
echo "Hi, I'm bash !"
sleep 1
doneFor me, this now takes 0.884 seconds to stop. Perfect!
Be careful, however: the script here catches SIGTERM signals but does not propagate them to child processes.
Using software made to be used as an init process
Finally, let’s say you really want to have multiple processes in your image, use complex bash shells that call your program, and other situations.
Well, there exist solutions such as tini. Tini is a lightweight init command that handles signal propagation and zombie reaping. Easy to install, easy to use, and makes your containers healthier!
Conclusion
To conclude, we had to dive deep inside Unix process management to understand the root of our signal propagation problem, but the good news is that it’s quite simple to fix, and has a huge impact on a Docker container’s lifecycle.
There are many more Docker good practices that can greatly improve your application’s health and its effectiveness. For example, we covered multi stage builds in another article. Here are the good practices that docker recommends.





